This article mainly shares the python3.x crawler technology that I have recently practiced and gotten into practice, and I made a simple attempt in the school library, and I can successfully reserve my favorite seat (of course, it is for learning only, not recommended This script is opportunistic and disrupts the order of appointments).
First of all, let me briefly introduce my learning process of completing the script from scratch.
- Use fiddler to capture packets from port 8888 and parse each session
- The get and post methods of request in http, the content of request headers and the role of cookies
- The use of request and response in the urllib package
- Use BeautifulSoup to parse HTML pages
- How to use datetime in python3
It takes some time to learn these techniques for beginners. After you become proficient, you will find that crawling is a kind of practice that makes perfect. Practicing more will make you deal with various unexpected situations more quickly. Let me introduce the process of my step-by-step analysis.
Mock login
Preparation work
First open the fiddler software and open it in the chrome browserWuhan University Library Reservation Official Website。
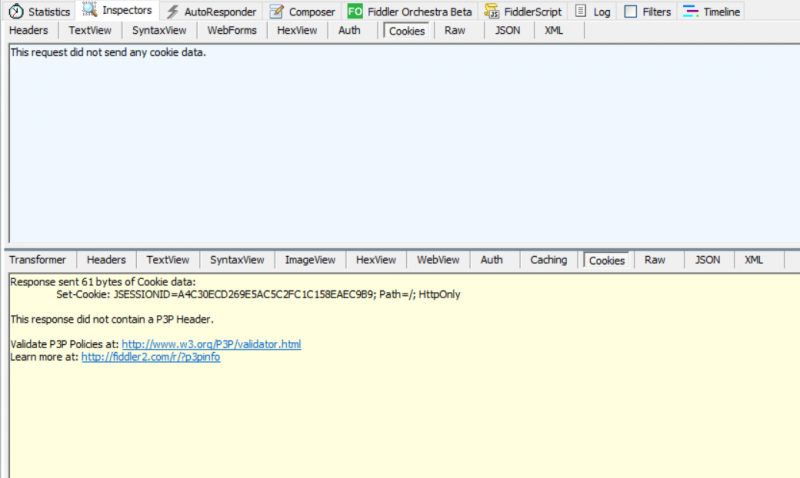
I found that there was a jump. Based on the experience of many exercises, when you directly access the host without suffix, you will get a cookie for subsequent login verification and verification code generation. Check session 16
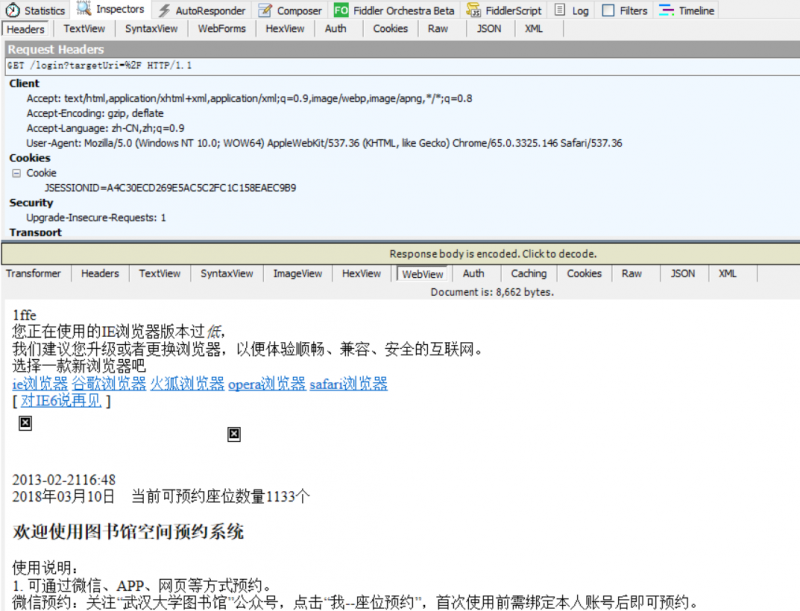
The HTTP request did not contain any cookie information, and a cookie was returned. The returned cookie will be the basis for login and subsequent operations. Check the 17th session to verify our guess

It can be seen that the request to redirect the link carried the cookie that was just obtained, and returned to the login interface, so that the cookie has been obtained.
Next, enter your student ID and password in the login interface, and found an important detail. The library’s webpage login has a verification code, which will be a big trouble for crawlers. At first, I wanted to solve the problem of verification code recognition through some APIs. To solve this problem, after using Baidu ocr recognition and Google tesseract, I found that the effect is not satisfactory, and the error rate is too high. If you want more accurate recognition, you need to train your own deep learning neural network, which is too cumbersome, in order to complete the crawler project faster , Put down these advanced tasks for the time being, for this I adopted the method of directly displaying the captcha image and manually inputting it. The link to view the verification code is /simpleCaptcha/captcha. It is found in fiddler that every time the verification code is requested, the address carries the initial cookie, so that the verification code will not be refreshed. This is good news for crawlers. Long valid time can guarantee absolute validity after user input.
The login is successful in the browser, and the request to view the login is the post method. The data carried are username, password, captcha, and the address is /auth/signIn
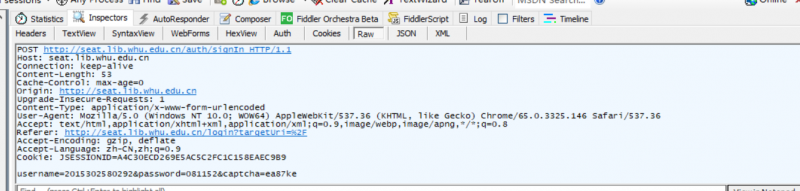
Start simulation
The first is the basic Request initialization work. Pay attention to the post method with data. Request without data is the get method. The post method is mainly used for form submission and data submission. Most of the requests for the address are the get method. . Another thing to mention is that the request.urlopen method is a special opener. If you want to get a cookie, you should build an opener with a cookie yourself. If you don’t need a cookie, just use this method.
index_url = 'http://seat.lib.whu.edu.cn/'
cookie = cookiejar.CookieJar()
handler = request.HTTPCookieProcessor(cookie)
opener = request.build_opener(handler)
index_req = request.Request(index_url)
index_req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36')
index_res = opener.open(index_req)
index_cookie = ''
for item in cookie:
index_cookie += item.name + '=' + item.value + ';'
The above code shows how to get index_cookie from the visiting host Then there is the capture of the verification code image. Note that the cookie must be added to the headers in the request to ensure that the verification code is valid for a long time. The crawled data is only a bunch of binary characters that need to be written to the file ( In the open method,’wb’ stands for write and’rb’ stands for read). In addition, the pillow package (PIL) is also needed, and the PIL plug-in is used to display the picture so that we can directly see the verification code.
captcha_url='http://seat.lib.whu.edu.cn/simpleCaptcha/captcha'
req=request.Request(captcha_url,headers=headers)
res=request.urlopen(req)
with open('captcha.png','wb') as fp:
fp.write(res.read())
image=Image.open('captcha.png')
if image:
print('验证码已经获取')
image.show()
After the verification code is obtained, the user can enter the characters they see, and the data required for login is also collected. The data can be submitted to the server using the post method below, so that the local cookie can be registered in the host server for a long time. According to the cookie information returned by fiddler, it can be known that the validity time of this cookie is two hours.
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36',
'Cookie':index_cookie
}
login_url='http://seat.lib.whu.edu.cn/auth/signIn'
login_data={
'username':username,
'password':password,
'captcha':captcha
}
login_req=request.Request(login_url,parse.urlencode(login_data).encode(),headers)
login_res=request.urlopen(login_req)
Since the headers in the above code have been registered, they can be used for a long time. All the following request headers are this.
So far, the simulated login has been completed.
Query seat
Find the interface
Introduce the seat distribution of the Library of the Information Department of Wuhan University. The library has four floors. The first floor is the discussion area and the computer area. The seats in the discussion area are round table-shaped, not suitable for self-study, and because they usually use their own The computer area is basically useless, so on the first floor pass, there are two study rooms on each floor from the second floor, and there is an autonomous study area on the third floor, so the seats in these seven rooms are the original The target of this crawler appointment.
When I first started writing the crawler, my idea was to directly look for the reserved seat address to make a reservation. Starting from the west room on the second floor, if the reservation fails, then reserve the next seat in the current room until there is a seat that meets the requirements. , But in actual practice, due to frequent reservation requests, apart from all kinds of return exceptions, the library server will also have a corresponding anti-crawler mechanism to block the current IP. In severe cases, the student ID will be blocked. Therefore, I adjusted my appointment strategy to focus on search, and the final appointment request should be as few as possible.
Observing the homepage of the library, I found that the library directly provides the seat query function, so click this function to query and use fiddler to capture the packet. The web page results and the packet capture results are as follows.
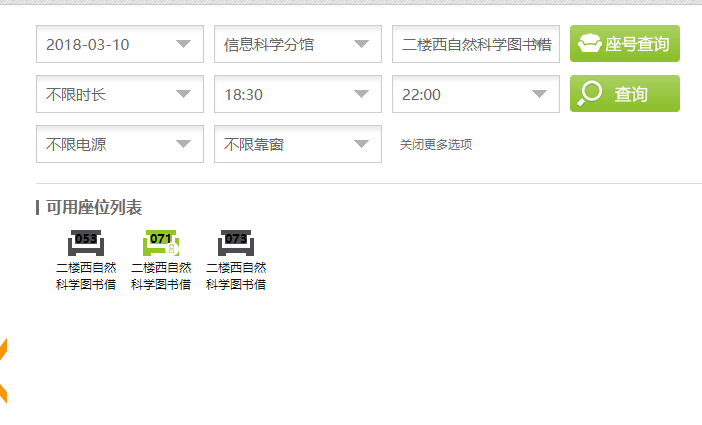
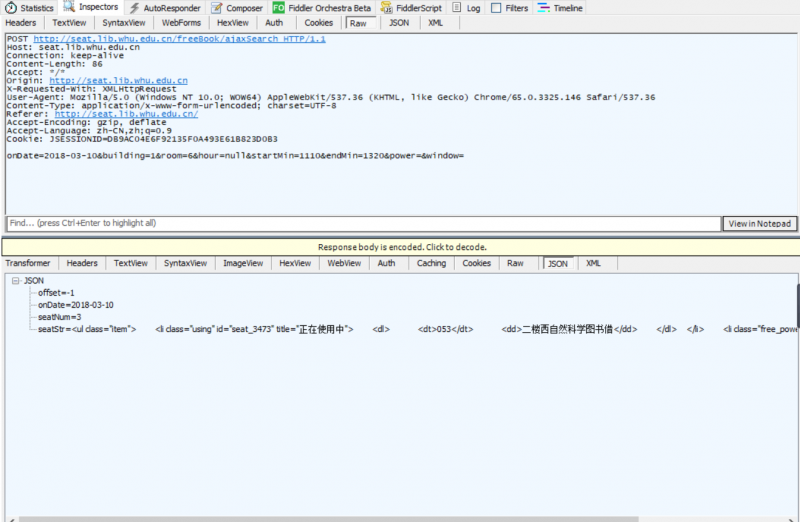
It is not difficult to find that the post method is used to request, and the return is a json file, where the seatStr field is the html of the available seat list, the id attribute of each li tag is the id of the current seat, and the dt tag corresponds to this id For the seat number in the room, for simplicity, we can extract the first seat with the label li and make a reservation.
Extract the seat id
The next important task is how to parse the json file and html to obtain the final seat id and seat number (for display). The seat id will be the main data for the final reservation. Looking at this session, you can know that the data that needs to be posted are onDate, building (only the library of the Ministry of Information is considered here, the building number is 1), room, hour, startMin, endMin, power (whether a power seat is required), window (whether it is by the window or not) ), set some data at will for experimentation below.
The tool for parsing json is the json package that comes with python. Use json.loads to convert json format files into python dictionary structure. After getting the dictionary, first use the key of seatNum to get the number of available seats in the current room. If it is 0, you can start the query of the next room. If it is not 0, query seatStr to get the html of the seat.
After getting the html, you need to use BeautifulSoup to convert it into a soup object. There are several parsing modes for beautifulsoup, such as lxml, html.parser, xml, etc. Here, html.parser is used for parsing. After obtaining the soup object, observe the html content and find each one The seats are all in the li tag, and the seat number of each seat is in the dt tag, so using soup.p (p is the tag name, the first tag is returned) can directly get the first seat that is queried, and then Use .attrs(‘attribute name’) to get the content of the id attribute, and then use the method of intercepting the string from back to front. code show as below:\
search_url = 'http://seat.lib.whu.edu.cn/freeBook/ajaxSearch'
search_data = {
'onDate': date,
'building': '1',
'room':room,
'hour':'null',
'startMin':start_time,
'endMin':end_time,
'power':'null',
'window':'1',
}
search_req=request.Request(search_url,parse.urlencode(search_data).encode(),headers)
search_res=request.urlopen(search_req)
search_json=json.loads(search_res.read().decode('utf-8'))
if search_json['seatNum']!=0:
find=True
seat_html=search_json['seatStr']
seat_soup=BeautifulSoup(seat_html,'html.parser')
seat_id=seat_soup.li.attrs['id'][-4:]
seat_num=seat_soup.dt.text
Search optimization
I noticed that there is a window seat and a non-window seat. For my own selfishness, of course, I have to reserve the window seat first. Therefore, I arranged two queries before and after, first check the window seat, if no seat is found Then check the seats that are not by the window. The structure of various cycles is no longer posted here.
Seat reservation
Capture package preparation
Try to make a seat reservation by yourself, and find out the information returned by various reservation results.

It is found that all the returned information is in the dd label, and you can make an appointment and print the result according to this clue.
Make an appointment
The same is to post the reserved address, directly use BeautifulSoup to parse, use the findAll method, and print the obtained list separately. Of course, you need to use this cookie to get the verification code again before making an appointment.
getCaptcha(headers)
captcha=input('请输入预定验证码')
book_data={
'date':date,
'seat':seat_id,
'start':start_time,
'end':end_time,
'captcha':captcha
}
book_req=request.Request(book_url,parse.urlencode(book_data).encode(),headers)
book_res=request.urlopen(book_req)
book_soup=BeautifulSoup(book_res.read().decode('utf-8'),'html.parser')
results=book_soup.find_all('dd')
for result in results:
if '成功' in result.text:
book=True
print(result.text)
In this way, the appointment is basically completed.
Program improvement
The completion of the basic functions does not mean that it can perfectly meet our needs. The seat grab time of the school is usually at half past ten, so it is best to let the program automatically run automatically at half past ten every day, this needs to be used The method in the datetime package uses the while infinite loop to get the current time each time. Because it also contains the number of microseconds, the time needs to be judged within one second between ten thirty and ten thirty, if it meets Execute the above program, note that here you need to pause for one second so that after the next cycle, it will not be in the current range, avoid executing the program multiple times, so that the effect of timing the program is achieved and the resource occupancy is very high. small.
if __name__=='__main__':
a=input('1、现在运行,2、定时运行(22:30)')
if a=='1':
function()
if a=='2':
schedual_time = datetime.datetime(2018, 3, 10, 22, 30, 0)
loop = 0
while True:
if schedual_time <= datetime.datetime.now() < schedual_time + datetime.timedelta(seconds=1):
loop = 1
time.sleep(1)
if loop == 1:
function()
loop == 0
Summarize
This crawler exercise basically covers all the mainstream technologies of crawler, as well as the application of some python data structures. After mastering it, it will lay a good foundation for more complex structured crawler work in the future. Of course, there are some later words, how to use the deep learning tensorflow framework to train a large number of similar captcha image sets to improve the accuracy of captcha recognition and improve the program experience, as well as the use of proxy IP and Gaussian random numbers to pause. Dealing with the anti-crawling mechanism of the current website, as well as the distributed crawler to improve the efficiency of the crawler, are areas that can be studied in depth in the future.
Address of this project, welcome everyone to come and read.